practical ggplot2
practising the grammar of graphics
Aurelien Ginolhac
3 May 2017
This practical aims at performing exploratory plots and how-to build layer by layer to be familiar with the grammar of graphics. In the last part, a supplementary exercise will focus on plotting genome-wide CNV. You will also learn to use the forcats package which allows you to adjust the ordering of categorical variables appearing on your plot.
Scatter plots
The mtcars dataset is provided by the ggplot2 library (have a look above at the first lines printed using the head() function). As for every (or near to every) function, most datasets shipped with a library contain also a useful help page (?).
Plot the fuel consumption on the y axis and the cars weight on the x axis.
The
geom_smooth()layer can be used to add a trend line. Try to overlay it to your scatter plot.
Tip
by default geom_smooth is using a loess regression (< 1,000 points) and adds standard error intervals.
- The
methodargument can be used to change the regression to a linear one:method = "lm" - to disable the ribbon of standard errors, set
se = FALSE
It would be more useful to draw a regression line on the scatter plot and without the standard error. Using the help (
?), adjust the relevant setting ingeom_smooth().- Ajust some aesthetics in order to:
- associate the shape of the points to the number of cylinders
- associate a colour gradient to the quarter mile time
- If you’re feeling succesful, try to adjust the colour gradient from yellow for fast accelerating cars to blue for slow accelerating cars.
- have a look at the R package viridis which provides palettes color-blind friendly and suitable for grey printing
Tip
The cyl variable is of type double, thus a continuous variable. To map as the shape aesthetics, mind coercing the variable to a factor
- Find a way to produce both of the following plots:
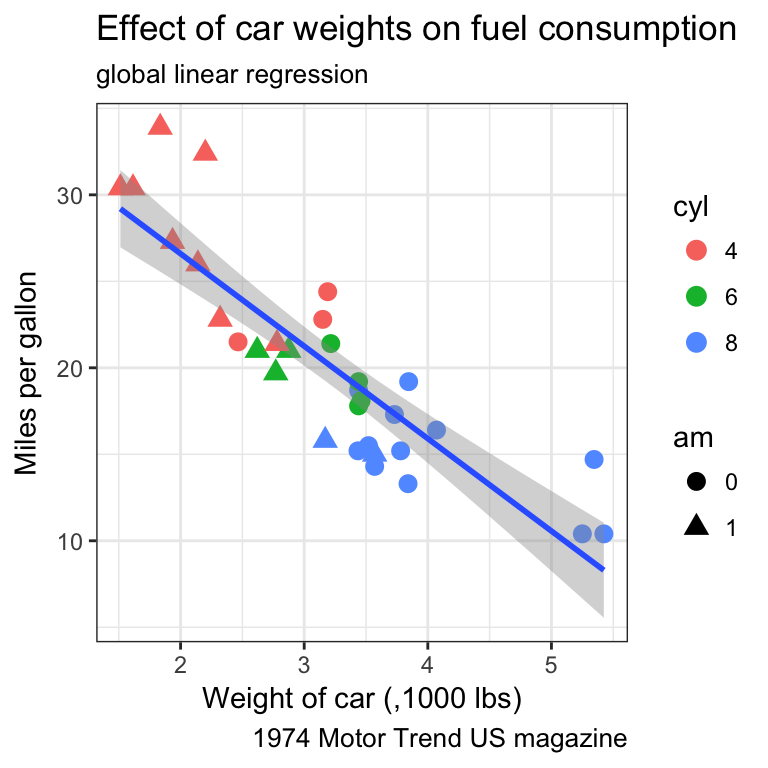
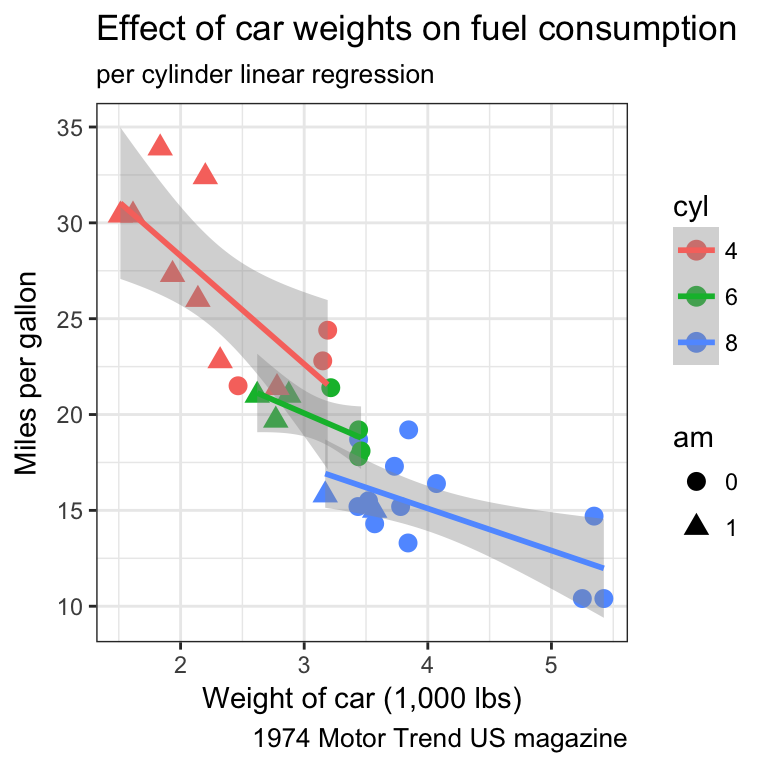
Tip
Remember that:
- all aesthetics defined in the
ggplot(aes())command will be inherited by all following layers aes()of individual geoms are specific (and overwrite the global definition if present).
Categorical data
We will now look at another built-in dataset called ToothGrowth. This dataset contains the teeth length of 60 guinea pigs which received 3 different doses of vitamin C (in mg/day), delivered either by orange juice (OJ) or ascorbic acid (VC).
Is this dataset tidy?
plot the distributions as boxplots of the teeth lengths by the dose received
attribute a different filling colour to each delivery method
When the dataset is tidy, it is easy to draw a plot telling us the story: vitamin C affects the teeth growth and the delivery method is only important for lower concentrations.
Boxplots are nice but misleading. The size of the dataset is not visible and the shapes of distrubutions could be better represented.
- plot again length of the teeth by the received dose but using
geom_dotplot()
Tip
change the following options in geom_dotplot():
binaxis = "y"for the y-axisstackdir = "center"binwidth = 1for no binning, display all dots
- add a
geom_violin()to the previous plot to get a better view of the distribution shape.
Tip
The order of the layers matters. Plotting is done respectively. Set the option trim = FALSE to the violin for a better looking shape
Now we are missing summary values like the median which is shown by the boxplots. We should add one.
- add the median using
stat_summary()to the previous plot
Tip
by default stat_summary() adds the mean and +/- standard error via geom_pointrange(). specify the fun.y = "median" and appropriate geom, colour.
next year replaces stat_summary(fun.y = "median", geom = "point", colour = "red", size = 4) by geom_point(stat = "summary", fun.y = "median", colour = "red", size = 4)
- change the
stat_summary()in the previous plot from median to mean_cl_boot and polish the labels.
different summary statistics from the library Hmisc are available. Let’s try the mean_cl_boot that computes the non-parametric bootstrap to obtain 95% confidence intervals (mean_cl_normal assumes normality)
Of note, a ggplot extension named ggbeeswarm proposes a very neat dotplot that fits the distribution.
ToothGrowth %>%
ggplot(aes(x = factor(dose), y = len)) +
ggbeeswarm::geom_quasirandom()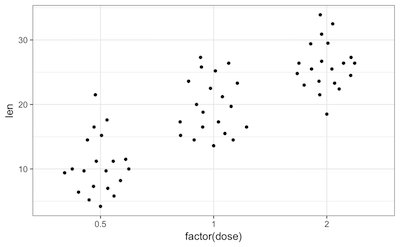
Supplementary exercises: genome-wide copy number variants (CNV) detection
Let’s have a look at a real output file for CNV detection. The used tool is called Reference Coverage Profiles: RCP. It was developed by analyzing the depth of coverage in over 6000 high quality (>40×) genomes. In the end, for every kb a state is assigned and similar states are merged eventually.
state means:
- 0, no coverage
- 1, deletion
- 2, expected diploidy
- 3, duplication
- 4, > 3 copies
Reading data
The file is accessible here. It is gzipped but readr will take care of the decompression. Actually, readr can even read the file directly from the website so you don’t need to download it locally.
CNV.seg.gz has 5 columns and the first 10 lines look like:
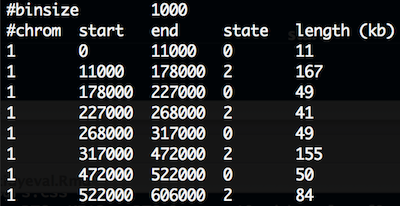
CNV
- load the file
CNV.seg.gzin R.
Warning
several issues must be fixed:
- comment should be discarded.
- chromosome will be read as integers since first 1000 lines are 1. But, X, Y are at the file’s end.
- first and last column names are unclean.
#chromcomtains a hash andlength (kb). Would be neater to fix this upfront.
exploratory plots
plot the counts of the different states. We expect a majority of diploid states.
plot the counts of the different states per chromosome. Might be worth freeing the count scale.
using the previous plot, reorder the levels of chromosomes to let them appear in the karyotype order (1:22, X, Y)
Tip
we could explicity provide the full levels lists in the desired order. However, in the tibble, the chromosomes appear in the wanted order. See the fct_inorder() function in the forcats package to take advantage of this.
- sexual chromosomes are not informative, collapse them into a gonosomes level
Tip
See the fct_collapse() function in the forcats
- plot the genomic segments length per state
Tip
- The distributions are completely skewed: transform to log-scale to get a decent plot.
- Add the summary mean and 95CI by bootstrap using the ToothGrowth example
count gain / loss summarising events per chromosome
filter the tibble only for autosomes and remove segments with no coverage and diploid (i.e states 0 and 2 respectively). Save as
cnv_auto.- We are left with state 1 and 3 and 4. Rename 1 as loss and the others as gain
- count the events per chromosome and per state
for loss counts, set them to negative so the barplot will be display up / down. Save as
cnv_auto_chrplot
cnv_auto_chrusing the count as theyvariable.
this is the final plot, where the following changes were made:
- labels of the
yaxis in absolute numbers - set
expand = c(0, 0)on thexaxis. see stackoverflow’s answer - use
theme_classic() - set the legend on the top right corner. Use a mix of
legend.positionandlegend.justificationin atheme()call. - remove the label of the
xaxis, you could use chromosomes if you prefer - change the color of the fill argument with
c("springgreen3", "steelblue2")
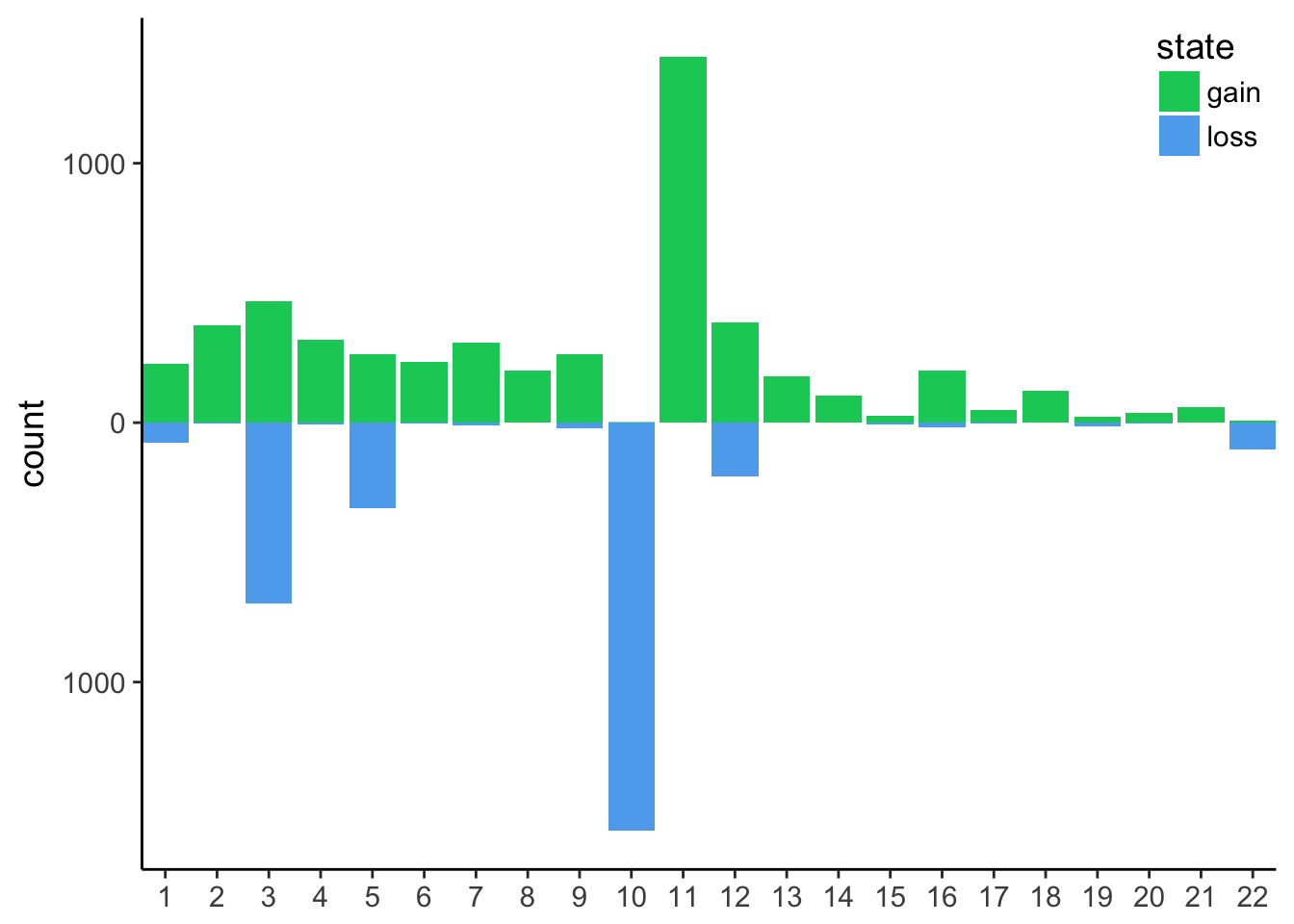
It is now obvious that we have mainly huge deletions on chromosome 10 and amplifications on chromosome 11.
In order to plot the genomic localisations of these events, we want to focus on the main chromosomes that were affected by amplifications/deletions.
- lump the chromsomes by the number of CNV events (states 1, 3 or 4) keeping the 5 top ones and plot the counts
Tip
the function fct_lump from forcats ease lumping. Just pick n = 5 to get the top 5 chromosomes
genomic plot of top 5 chromosomes
- plot the genomic localisations of CNV on the 5 main chromosomes