- (re)view some R base
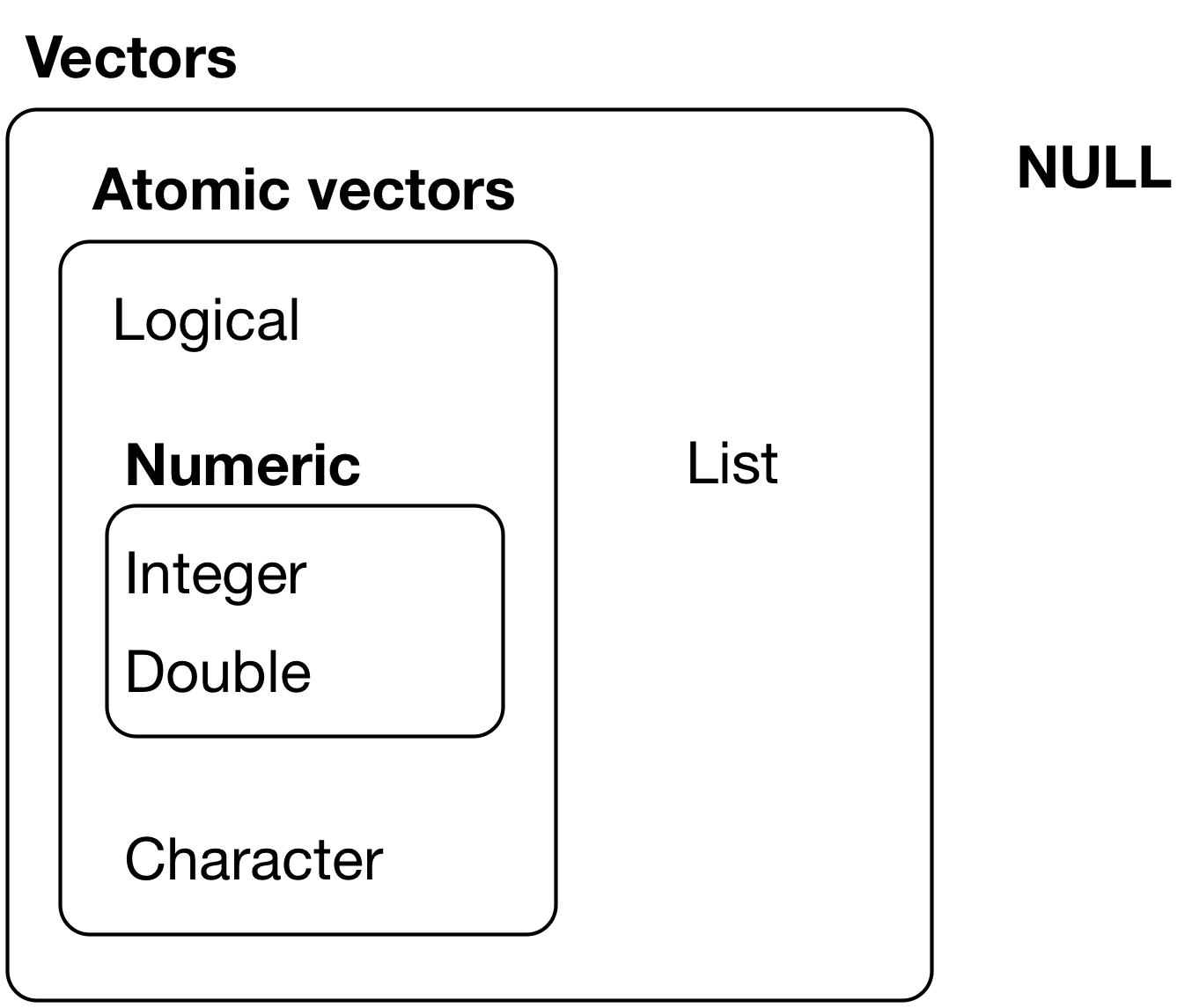
- get the different data types: numeric, logical, factor …
- understand what is a list, a vector, a data.frame …
| Type | Example |
|---|---|
| numeric | integer (2), double (2.34) |
| string | "tidyverse !" |
| boolean | TRUE / FALSE |
| complex | 2+0i |
Special case
NA # not available, missing data NA_real_ NA_integer_ NA_character_ NA_complex_ NULL # empty -Inf/Inf # infinite values