2nd June 2016
dplyr
dplyr - intro
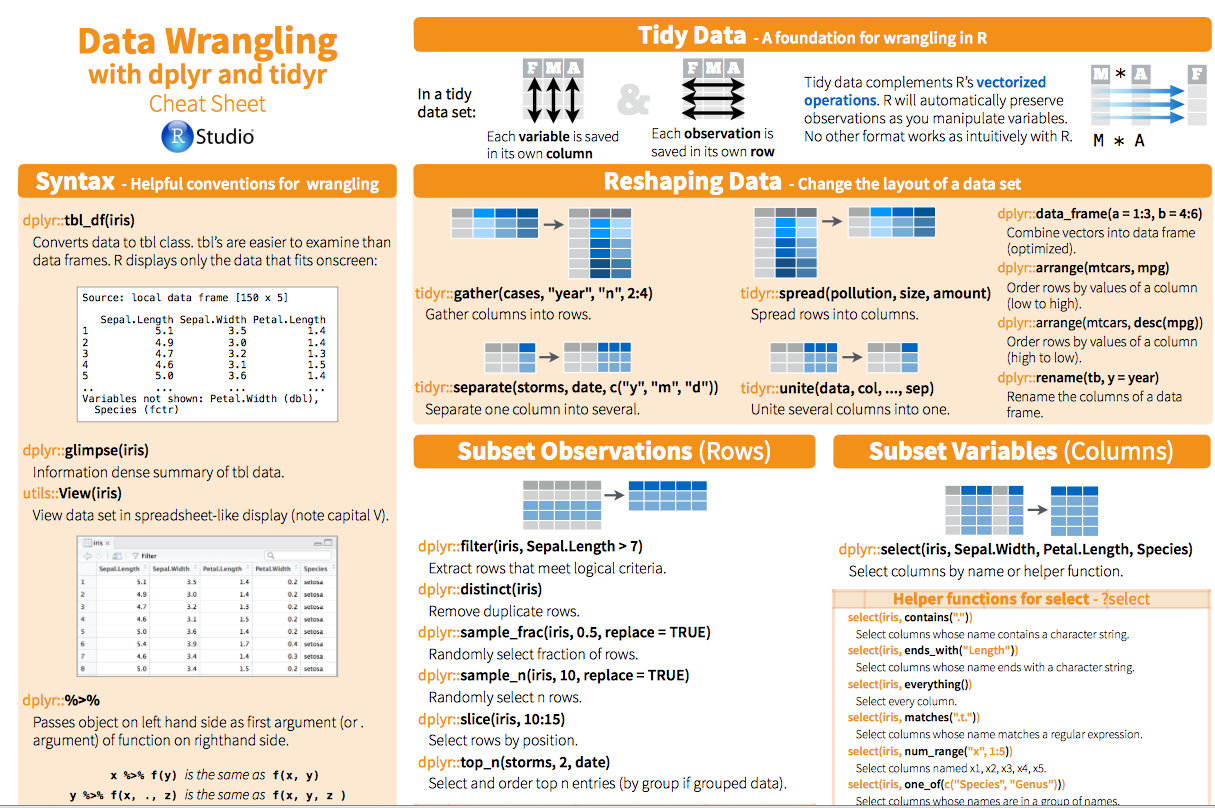
There's a cheatsheet!
with(mtcars, aggregate(mpg, list(cyl), mean))
## Group.1 x ## 1 4 26.66364 ## 2 6 19.74286 ## 3 8 15.10000
library("dplyr") # library("dplyr", warn.conflicts = FALSE)
mtcars %>%
group_by(cyl) %>%
summarize(mean(mpg))
## Source: local data frame [3 x 2] ## ## cyl mean(mpg) ## (dbl) (dbl) ## 1 4 26.66364 ## 2 6 19.74286 ## 3 8 15.10000
Web-based app to learn by practise
step-by-step tidying and manipulating data frames
nycflights13
flights is a tbl_df
library("dplyr", warn.conflicts = FALSE)
library("nycflights13")
flights
## Source: local data frame [336,776 x 19] ## ## year month day dep_time sched_dep_time dep_delay arr_time ## (int) (int) (int) (int) (int) (dbl) (int) ## 1 2013 1 1 517 515 2 830 ## 2 2013 1 1 533 529 4 850 ## 3 2013 1 1 542 540 2 923 ## 4 2013 1 1 544 545 -1 1004 ## 5 2013 1 1 554 600 -6 812 ## 6 2013 1 1 554 558 -4 740 ## 7 2013 1 1 555 600 -5 913 ## 8 2013 1 1 557 600 -3 709 ## 9 2013 1 1 557 600 -3 838 ## 10 2013 1 1 558 600 -2 753 ## .. ... ... ... ... ... ... ... ## Variables not shown: sched_arr_time (int), arr_delay (dbl), carrier (chr), ## flight (int), tailnum (chr), origin (chr), dest (chr), air_time (dbl), ## distance (dbl), hour (dbl), minute (dbl), time_hour (time)
glimpse
Use glimpse to show some values and types per column. Environment tab does it too
glimpse(flights)
## Observations: 336,776 ## Variables: 19 ## $ year (int) 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013,... ## $ month (int) 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,... ## $ day (int) 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,... ## $ dep_time (int) 517, 533, 542, 544, 554, 554, 555, 557, 557, 55... ## $ sched_dep_time (int) 515, 529, 540, 545, 600, 558, 600, 600, 600, 60... ## $ dep_delay (dbl) 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2... ## $ arr_time (int) 830, 850, 923, 1004, 812, 740, 913, 709, 838, 7... ## $ sched_arr_time (int) 819, 830, 850, 1022, 837, 728, 854, 723, 846, 7... ## $ arr_delay (dbl) 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -... ## $ carrier (chr) "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV",... ## $ flight (int) 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79... ## $ tailnum (chr) "N14228", "N24211", "N619AA", "N804JB", "N668DN... ## $ origin (chr) "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR"... ## $ dest (chr) "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL"... ## $ air_time (dbl) 227, 227, 160, 183, 116, 150, 158, 53, 140, 138... ## $ distance (dbl) 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 94... ## $ hour (dbl) 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5,... ## $ minute (dbl) 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, ... ## $ time_hour (time) 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013...
filter: inspect subsets of data
How many flights flew to La Guardia, NY in 2013? Expecting none…
flights %>% filter(dest == "LGA")
## Source: local data frame [1 x 19] ## ## year month day dep_time sched_dep_time dep_delay arr_time ## (int) (int) (int) (int) (int) (dbl) (int) ## 1 2013 7 27 NA 106 NA NA ## Variables not shown: sched_arr_time (int), arr_delay (dbl), carrier (chr), ## flight (int), tailnum (chr), origin (chr), dest (chr), air_time (dbl), ## distance (dbl), hour (dbl), minute (dbl), time_hour (time)
base version equivalent (subset could also be used)
flights[which(flights$dest == "LGA"), ]
## Source: local data frame [1 x 19] ## ## year month day dep_time sched_dep_time dep_delay arr_time ## (int) (int) (int) (int) (int) (dbl) (int) ## 1 2013 7 27 NA 106 NA NA ## Variables not shown: sched_arr_time (int), arr_delay (dbl), carrier (chr), ## flight (int), tailnum (chr), origin (chr), dest (chr), air_time (dbl), ## distance (dbl), hour (dbl), minute (dbl), time_hour (time)
filter: multiple conditions AND (&)
How many flights flew to Madison in first week of January?
# Comma separated conditions are combined with '&' flights %>% filter(dest == "MSN", month == 1, day <= 7)
## Source: local data frame [6 x 19] ## ## year month day dep_time sched_dep_time dep_delay arr_time ## (int) (int) (int) (int) (int) (dbl) (int) ## 1 2013 1 1 1353 1357 -4 1549 ## 2 2013 1 2 1422 1357 25 1604 ## 3 2013 1 3 1415 1351 24 1540 ## 4 2013 1 4 1345 1350 -5 1525 ## 5 2013 1 6 1340 1345 -5 1506 ## 6 2013 1 7 1348 1350 -2 1625 ## Variables not shown: sched_arr_time (int), arr_delay (dbl), carrier (chr), ## flight (int), tailnum (chr), origin (chr), dest (chr), air_time (dbl), ## distance (dbl), hour (dbl), minute (dbl), time_hour (time)
filter: multiple conditions OR
flights %>% filter(dest == "MSN" | dest == "ORD" | dest == "MDW")
For more complicated checks, prefer a set operation.
The following 2 are equivalent:
flights %>%
filter(is.element(dest, c("MSN", "ORD", "MDW")))
flights %>%
filter(dest %in% c("MSN", "ORD", "MDW"))
arrange: sort columns
Perform a nested sorting of all flights in NYC:
1. By which airport they departed 2. year 3. month 4. day
flights %>% arrange(origin, year, month, day)
## Source: local data frame [336,776 x 19] ## ## year month day dep_time sched_dep_time dep_delay arr_time ## (int) (int) (int) (int) (int) (dbl) (int) ## 1 2013 1 1 517 515 2 830 ## 2 2013 1 1 554 558 -4 740 ## 3 2013 1 1 555 600 -5 913 ## 4 2013 1 1 558 600 -2 923 ## 5 2013 1 1 559 600 -1 854 ## 6 2013 1 1 601 600 1 844 ## 7 2013 1 1 606 610 -4 858 ## 8 2013 1 1 607 607 0 858 ## 9 2013 1 1 608 600 8 807 ## 10 2013 1 1 615 615 0 833 ## .. ... ... ... ... ... ... ... ## Variables not shown: sched_arr_time (int), arr_delay (dbl), carrier (chr), ## flight (int), tailnum (chr), origin (chr), dest (chr), air_time (dbl), ## distance (dbl), hour (dbl), minute (dbl), time_hour (time)
arrange desc: reverses sorting
Find the longest delays for flights to Madison.
flights %>% filter(dest == "MSN") %>% arrange(desc(arr_delay)) %>% select(arr_delay, everything()) # way to reorder arr_delay 1st column
## Source: local data frame [572 x 19] ## ## arr_delay year month day dep_time sched_dep_time dep_delay arr_time ## (dbl) (int) (int) (int) (int) (int) (dbl) (int) ## 1 364 2013 9 12 1841 1350 291 2135 ## 2 337 2013 12 5 2000 1420 340 2132 ## 3 301 2013 10 7 1912 1425 287 2048 ## 4 298 2013 3 8 1907 1405 302 2031 ## 5 293 2013 3 14 1845 1405 280 2026 ## 6 274 2013 11 17 45 1935 310 206 ## 7 274 2013 6 30 1855 1415 280 2013 ## 8 264 2013 10 11 1857 1425 272 2011 ## 9 247 2013 2 6 2242 1825 257 15 ## 10 222 2013 12 31 1819 1505 194 2023 ## .. ... ... ... ... ... ... ... ... ## Variables not shown: sched_arr_time (int), carrier (chr), flight (int), ## tailnum (chr), origin (chr), dest (chr), air_time (dbl), distance (dbl), ## hour (dbl), minute (dbl), time_hour (time)
Find the most delayed (in minutes) flight in 2013
flights %>% arrange(desc(arr_delay)) %>% select(arr_delay, everything()) %>% head(3)
## Source: local data frame [3 x 19] ## ## arr_delay year month day dep_time sched_dep_time dep_delay arr_time ## (dbl) (int) (int) (int) (int) (int) (dbl) (int) ## 1 1272 2013 1 9 641 900 1301 1242 ## 2 1127 2013 6 15 1432 1935 1137 1607 ## 3 1109 2013 1 10 1121 1635 1126 1239 ## Variables not shown: sched_arr_time (int), carrier (chr), flight (int), ## tailnum (chr), origin (chr), dest (chr), air_time (dbl), distance (dbl), ## hour (dbl), minute (dbl), time_hour (time)
1272 / 60
## [1] 21.2
select columns
flights %>% select(origin, year, month, day)
## Source: local data frame [336,776 x 4] ## ## origin year month day ## (chr) (int) (int) (int) ## 1 EWR 2013 1 1 ## 2 LGA 2013 1 1 ## 3 JFK 2013 1 1 ## 4 JFK 2013 1 1 ## 5 LGA 2013 1 1 ## 6 EWR 2013 1 1 ## 7 EWR 2013 1 1 ## 8 LGA 2013 1 1 ## 9 JFK 2013 1 1 ## 10 LGA 2013 1 1 ## .. ... ... ... ...
select's helpers
select has many helper functions. See ?select.
works with tidyr functions too
flights %>%
select(origin, year:day, starts_with("dep"))
## Source: local data frame [336,776 x 6] ## ## origin year month day dep_time dep_delay ## (chr) (int) (int) (int) (int) (dbl) ## 1 EWR 2013 1 1 517 2 ## 2 LGA 2013 1 1 533 4 ## 3 JFK 2013 1 1 542 2 ## 4 JFK 2013 1 1 544 -1 ## 5 LGA 2013 1 1 554 -6 ## 6 EWR 2013 1 1 554 -4 ## 7 EWR 2013 1 1 555 -5 ## 8 LGA 2013 1 1 557 -3 ## 9 JFK 2013 1 1 557 -3 ## 10 LGA 2013 1 1 558 -2 ## .. ... ... ... ... ... ...
negative selecting
We can drop columns by "negating" the name. Since helpers give us column names, we can negate them too.
flights %>%
select(-dest, -starts_with("arr"),
-ends_with("time"))
## Source: local data frame [336,776 x 12] ## ## year month day dep_delay carrier flight tailnum origin distance ## (int) (int) (int) (dbl) (chr) (int) (chr) (chr) (dbl) ## 1 2013 1 1 2 UA 1545 N14228 EWR 1400 ## 2 2013 1 1 4 UA 1714 N24211 LGA 1416 ## 3 2013 1 1 2 AA 1141 N619AA JFK 1089 ## 4 2013 1 1 -1 B6 725 N804JB JFK 1576 ## 5 2013 1 1 -6 DL 461 N668DN LGA 762 ## 6 2013 1 1 -4 UA 1696 N39463 EWR 719 ## 7 2013 1 1 -5 B6 507 N516JB EWR 1065 ## 8 2013 1 1 -3 EV 5708 N829AS LGA 229 ## 9 2013 1 1 -3 B6 79 N593JB JFK 944 ## 10 2013 1 1 -2 AA 301 N3ALAA LGA 733 ## .. ... ... ... ... ... ... ... ... ... ## Variables not shown: hour (dbl), minute (dbl), time_hour (time)
Recap: Verbs for inspecting data
- convert to a
tbl_df. Now in[tibble](https://github.com/hadley/tibble) glimpse- some of each columnfilter- subsettingarrange- sorting (descto reverse the sort)select- picking (and omitting) columns
rename
Rename columns with rename(NewName = OldName). To keep the order correct, read/remember the renaming = as "was".
flights %>% rename(y = year, m = month, d = day)
## Source: local data frame [336,776 x 19] ## ## y m d dep_time sched_dep_time dep_delay arr_time ## (int) (int) (int) (int) (int) (dbl) (int) ## 1 2013 1 1 517 515 2 830 ## 2 2013 1 1 533 529 4 850 ## 3 2013 1 1 542 540 2 923 ## 4 2013 1 1 544 545 -1 1004 ## 5 2013 1 1 554 600 -6 812 ## 6 2013 1 1 554 558 -4 740 ## 7 2013 1 1 555 600 -5 913 ## 8 2013 1 1 557 600 -3 709 ## 9 2013 1 1 557 600 -3 838 ## 10 2013 1 1 558 600 -2 753 ## .. ... ... ... ... ... ... ... ## Variables not shown: sched_arr_time (int), arr_delay (dbl), carrier (chr), ## flight (int), tailnum (chr), origin (chr), dest (chr), air_time (dbl), ## distance (dbl), hour (dbl), minute (dbl), time_hour (time)
mutate
- How much departure delay did the flight make up in the air?
- Note that new variables can be used right away
flights %>%
mutate(
gain = arr_delay - dep_delay,
speed = (distance / air_time) * 60,
gain_per_hour = gain / (air_time / 60)) %>%
select(gain:gain_per_hour)
## Source: local data frame [336,776 x 3] ## ## gain speed gain_per_hour ## (dbl) (dbl) (dbl) ## 1 9 370.0441 2.378855 ## 2 16 374.2731 4.229075 ## 3 31 408.3750 11.625000 ## 4 -17 516.7213 -5.573770 ## 5 -19 394.1379 -9.827586 ## 6 16 287.6000 6.400000 ## 7 24 404.4304 9.113924 ## 8 -11 259.2453 -12.452830 ## 9 -5 404.5714 -2.142857 ## 10 10 318.6957 4.347826 ## .. ... ... ...
Could the gain be explained by speed?
library("ggplot2")
flights %>%
mutate(gain = arr_delay - dep_delay,
speed = (distance / air_time) * 60) %>%
sample_n(10000) %>% # subsample 1e5 rows randomly
ggplot(aes(x = gain, y = speed))+
geom_point(alpha = 0.4)

group_by
For the flights to Madison, let's compute the average delay per month.
instead of aggregate, dplyr has its own grouping function.
Here, we group_by date. See the helpful reminder from tbl_df print method
flights %>% filter(dest == "MSN") %>% group_by(month) %>% #Some values are missing, thus tell `mean` to remove them from the calculation. summarise(mean_dep_delay = mean(dep_delay, na.rm = TRUE))
## Source: local data frame [12 x 2] ## ## month mean_dep_delay ## (int) (dbl) ## 1 1 18.07692 ## 2 2 20.11111 ## 3 3 41.87097 ## 4 4 29.40741 ## 5 5 21.54839 ## 6 6 29.83333 ## 7 7 11.13333 ## 8 8 19.06667 ## 9 9 15.97183 ## 10 10 19.26190 ## 11 11 15.96250 ## 12 12 42.68831
group_by (2)
Work per day, note the tibble info about the 365 groupings
by_day <- flights %>% group_by(year, month, day) by_day
## Source: local data frame [336,776 x 19] ## Groups: year, month, day [365] ## ## year month day dep_time sched_dep_time dep_delay arr_time ## (int) (int) (int) (int) (int) (dbl) (int) ## 1 2013 1 1 517 515 2 830 ## 2 2013 1 1 533 529 4 850 ## 3 2013 1 1 542 540 2 923 ## 4 2013 1 1 544 545 -1 1004 ## 5 2013 1 1 554 600 -6 812 ## 6 2013 1 1 554 558 -4 740 ## 7 2013 1 1 555 600 -5 913 ## 8 2013 1 1 557 600 -3 709 ## 9 2013 1 1 557 600 -3 838 ## 10 2013 1 1 558 600 -2 753 ## .. ... ... ... ... ... ... ... ## Variables not shown: sched_arr_time (int), arr_delay (dbl), carrier (chr), ## flight (int), tailnum (chr), origin (chr), dest (chr), air_time (dbl), ## distance (dbl), hour (dbl), minute (dbl), time_hour (time)
Note that one level (right most) is removed from grouping.
summarise
Now we use summarise to compute (several) aggregate values within each group (per day). summarise returns one row per group.
by_day %>%
summarise(
flights = n(), # dplyr specific function
avg_delay = mean(dep_delay, na.rm = TRUE),
n_planes = n_distinct(tailnum)) # dplyr specific function
## Source: local data frame [365 x 6] ## Groups: year, month [?] ## ## year month day flights avg_delay n_planes ## (int) (int) (int) (int) (dbl) (int) ## 1 2013 1 1 842 11.548926 649 ## 2 2013 1 2 943 13.858824 712 ## 3 2013 1 3 914 10.987832 689 ## 4 2013 1 4 915 8.951595 689 ## 5 2013 1 5 720 5.732218 578 ## 6 2013 1 6 832 7.148014 640 ## 7 2013 1 7 933 5.417204 682 ## 8 2013 1 8 899 2.553073 667 ## 9 2013 1 9 902 2.276477 666 ## 10 2013 1 10 932 2.844995 689 ## .. ... ... ... ... ... ...
Exercice
In average, how many flights does a single plane perform each day?
plot the distribution, display the mean / median (
geom_vline())plot the average delay per day. Use
tidyr:uniteandas.Datewhich day should be avoided?
Solution 1
by_day %>%
summarise(flights = n(),
avg_delay = mean(dep_delay, na.rm = TRUE),
n_planes = n_distinct(tailnum)) %>%
mutate(avg_flights = flights / n_planes)
## Source: local data frame [365 x 7] ## Groups: year, month [12] ## ## year month day flights avg_delay n_planes avg_flights ## (int) (int) (int) (int) (dbl) (int) (dbl) ## 1 2013 1 1 842 11.548926 649 1.297381 ## 2 2013 1 2 943 13.858824 712 1.324438 ## 3 2013 1 3 914 10.987832 689 1.326560 ## 4 2013 1 4 915 8.951595 689 1.328012 ## 5 2013 1 5 720 5.732218 578 1.245675 ## 6 2013 1 6 832 7.148014 640 1.300000 ## 7 2013 1 7 933 5.417204 682 1.368035 ## 8 2013 1 8 899 2.553073 667 1.347826 ## 9 2013 1 9 902 2.276477 666 1.354354 ## 10 2013 1 10 932 2.844995 689 1.352685 ## .. ... ... ... ... ... ... ...
Solution 2
by_day %>%
summarise(flights = n(),
avg_delay = mean(dep_delay, na.rm = TRUE),
n_planes = n_distinct(tailnum)) %>%
mutate(avg_flights = flights / n_planes) %>%
ggplot()+
geom_density(aes(x = avg_flights))+
geom_vline(aes(xintercept = mean(avg_flights)), colour = "red")+
geom_vline(aes(xintercept = median(avg_flights)), colour = "blue")

Solution 3
library("tidyr")
by_day %>%
summarise(avg_delay = mean(dep_delay, na.rm = TRUE)) %>%
ungroup() %>%
unite(date, -avg_delay, sep = "-") %>%
mutate(date = as.Date(date)) %>%
ggplot()+geom_bar(aes(x = date, y = avg_delay), stat = "identity")

Solution 3
by_day %>% summarise(avg_delay = mean(dep_delay, na.rm = TRUE)) %>% arrange(desc(avg_delay))
## Source: local data frame [365 x 4] ## Groups: year, month [12] ## ## year month day avg_delay ## (int) (int) (int) (dbl) ## 1 2013 1 31 28.65836 ## 2 2013 1 30 28.62344 ## 3 2013 1 16 24.61287 ## 4 2013 1 25 21.89853 ## 5 2013 1 13 19.87315 ## 6 2013 1 24 19.46542 ## 7 2013 1 28 15.13853 ## 8 2013 1 2 13.85882 ## 9 2013 1 22 12.49944 ## 10 2013 1 1 11.54893 ## .. ... ... ... ...
What's wrong?
Solution 3.2
Mind that arrange uses grouping! (will change in version 0.4.5)
by_day %>% summarise(avg_delay = mean(dep_delay, na.rm = TRUE)) %>% ungroup %>% arrange(desc(avg_delay))
## Source: local data frame [365 x 4] ## ## year month day avg_delay ## (int) (int) (int) (dbl) ## 1 2013 3 8 83.53692 ## 2 2013 7 1 56.23383 ## 3 2013 9 2 53.02955 ## 4 2013 7 10 52.86070 ## 5 2013 12 5 52.32799 ## 6 2013 5 23 51.14472 ## 7 2013 9 12 49.95875 ## 8 2013 6 28 48.82778 ## 9 2013 6 24 47.15742 ## 10 2013 7 22 46.66705 ## .. ... ... ... ...
Exercice
- Find the destinations with the highest average arrival delay?
- discard flights with missing arrival delays
- count the number of flights per destination
- discard results with less than 10 flights: mean will not be meaningful
Solution
flights %>%
filter(!is.na(arr_delay)) %>%
group_by(dest) %>%
summarise(mean = mean(arr_delay),
n = n()) %>%
filter(n > 10) %>%
arrange(desc(mean))
## Source: local data frame [101 x 3] ## ## dest mean n ## (chr) (dbl) (int) ## 1 CAE 41.76415 106 ## 2 TUL 33.65986 294 ## 3 OKC 30.61905 315 ## 4 JAC 28.09524 21 ## 5 TYS 24.06920 578 ## 6 MSN 20.19604 556 ## 7 RIC 20.11125 2346 ## 8 CAK 19.69834 842 ## 9 DSM 19.00574 523 ## 10 GRR 18.18956 728 ## .. ... ... ...
Is there a spatial pattern for those delays?
First get the GPS coordinate of airports using the data frame airports
airports
## Source: local data frame [1,396 x 7] ## ## faa name lat lon alt tz ## (chr) (chr) (dbl) (dbl) (int) (dbl) ## 1 04G Lansdowne Airport 41.13047 -80.61958 1044 -5 ## 2 06A Moton Field Municipal Airport 32.46057 -85.68003 264 -5 ## 3 06C Schaumburg Regional 41.98934 -88.10124 801 -6 ## 4 06N Randall Airport 41.43191 -74.39156 523 -5 ## 5 09J Jekyll Island Airport 31.07447 -81.42778 11 -4 ## 6 0A9 Elizabethton Municipal Airport 36.37122 -82.17342 1593 -4 ## 7 0G6 Williams County Airport 41.46731 -84.50678 730 -5 ## 8 0G7 Finger Lakes Regional Airport 42.88356 -76.78123 492 -5 ## 9 0P2 Shoestring Aviation Airfield 39.79482 -76.64719 1000 -5 ## 10 0S9 Jefferson County Intl 48.05381 -122.81064 108 -8 ## .. ... ... ... ... ... ... ## Variables not shown: dst (chr)
join two data frames
delays <- flights %>%
filter(!is.na(arr_delay)) %>%
group_by(dest) %>%
summarise(mean = mean(arr_delay),
n = n()) %>%
filter(n > 10) %>%
arrange(desc(mean)) %>%
inner_join(airports, by = c("dest" = "faa")) # provide the equivalence since columns have a different name
We could have used left_join but 4 rows with a 3-letters acronym have no correspondance in the airports data frame.
inner_join narrows down the lines that are present in both data frames.
join types

Of note: anti_join can select rows in which identifiers are absent in the second data frame.
plot on a map
library("ggplot2")
library("maps") # US map
ggplot(delays)+
geom_point(aes(x = lon, y = lat, colour = mean), size = 3, alpha = 0.8)+
scale_color_gradient2()+borders("state")

plot on a map, with text
library("ggrepel")
filter(delays, lon > -140) %>% # remove Honolulu
ggplot()+geom_point(aes(x = lon, y = lat, colour = mean), size = 3, alpha = 0.8)+
geom_text_repel(aes(x = lon, y = lat, label = name), size = 2.5)+
scale_color_gradient2()+theme_classic()+borders("state")

plot on a map, with conditional text
filter(delays, lon > -140) %>% # remove Honolulu
ggplot()+geom_point(aes(x = lon, y = lat, colour = mean),
size = 3, alpha = 0.8)+borders("state")+
geom_label_repel(data = delays %>% filter(mean > 20),
aes(x = lon, y = lat + 1, label = name), fill = "brown", colour = "white", size = 3)+
scale_color_gradient2()+theme_classic()

tally / count
tally is a shortcut to counting the number of items per group.
flights %>% group_by(dest, month) %>% tally() %>% head(3) # could sum up with multiple tally calls
## Source: local data frame [3 x 3] ## Groups: dest [1] ## ## dest month n ## (chr) (int) (int) ## 1 ABQ 4 9 ## 2 ABQ 5 31 ## 3 ABQ 6 30
count does the grouping for you
flights %>% count(dest, month) %>% head(3)
## Source: local data frame [3 x 3] ## Groups: dest [1] ## ## dest month n ## (chr) (int) (int) ## 1 ABQ 4 9 ## 2 ABQ 5 31 ## 3 ABQ 6 30
That covers 80% of dplyr
- select
- filter
- arrange
- glimpse
- rename
- mutate
- group_by, ungroup
- summarise
Other 20%
- assembly:
bind_rows,bind_cols - windows function,
min_rank,dense_rank,cumsum - column-wise operations:
mutate_each,transmute,summarise_each - join tables together:
right_join,full_join - filtering joins:
semi_join,anti_join do: arbitrary code on each chunk- different types of tabular data (databases, data.tables)
bind_rows + purrr
How to read in and merge files in 2 lines
library("purrr")
library("readxl")
files <- list.files(path = "./data/", pattern = "xlsx$", full.names = TRUE)
df <- lapply(files, read_excel) %>% bind_rows(.id = "file_number")
using purrr
purr_df <- map_df(files, read_excel, .id = "file_number")
filenames are better
library("stringr")
files %>%
set_names(nm = str_match(basename(.), "([^.]+)\\.[[:alnum:]]+$")[, 2]) %>%
map_df(read_excel, .id = "file_name") -> purr_name_df
Appendix
Coding style
R has a rather flexible and permissive syntax. However, being more strict tends to ease the debugging process.
long_function_name <- function(a = "a long argument",
b = "another argument",
c = "another long argument") {
# As usual code is indented by two spaces.
}
Useful rstudio shortcuts
- Scripting (replace Cmd by Ctrl for PC)
- Cmd + -: insert <-
- Cmd + Shift + M: insert %>%
- Alt + ↑ or ↓: move line up / down
- Cmd + Alt + ↑ or ↓: copy line up / down
- Ctrl + Alt + ↑ or ↓: multi-line edition
# analysis step ####for navigating- Running
- Cmd + Enter: run code
- Cmd + Shift + P: re-run Previous code
- Cmd + Shift + K: Knit document
Rstudio addins
Addins are small integrated packages that solve small tasks.

Dean Attali created a package to explore and manage your addins.
Sometimes, cause crashes
Recommended reading

Advanced in R by Hadley
- About R weirdness
See why: - <- and not = - :: and not ::: - library and not require etc.
Acknowledgments
- Hadley Wickham
- Steve Simpson
- Jenny Bryan
- Dean Attali
- David Robinson
- Eric Koncina